Lixoft Monolix Suite 2018 R2破解版是一款
用于制药学的非线性混合效应建模(NLME)的最先进和最简单的解决方案。用于非线性混合效应模型中的参数估计,模型诊断和评估以及高级图形表示的简单,快速且功能强大的工具。它基于SAEM算法,即使对于复杂的PK / PD模型也能提供强大的全局收敛。 Monolix用于临床前和临床人群PK / PD建模和系统药理学。 Monolix拥有庞大的用户社区。 Monolix被学术界,制药业以及美国监管机构广泛使用。本次小编带来的是Lixoft Monolix最新破解版,许可证文件和破解激活教程!
安装破解教程
1、在本站下载并解压,得到monolixsuite2018R2-installer.exe安装程序和AMPED破解文件夹

2、在破解文件夹中rlm_lixoft_win
运行rlm.exe(或将其设置为服务)
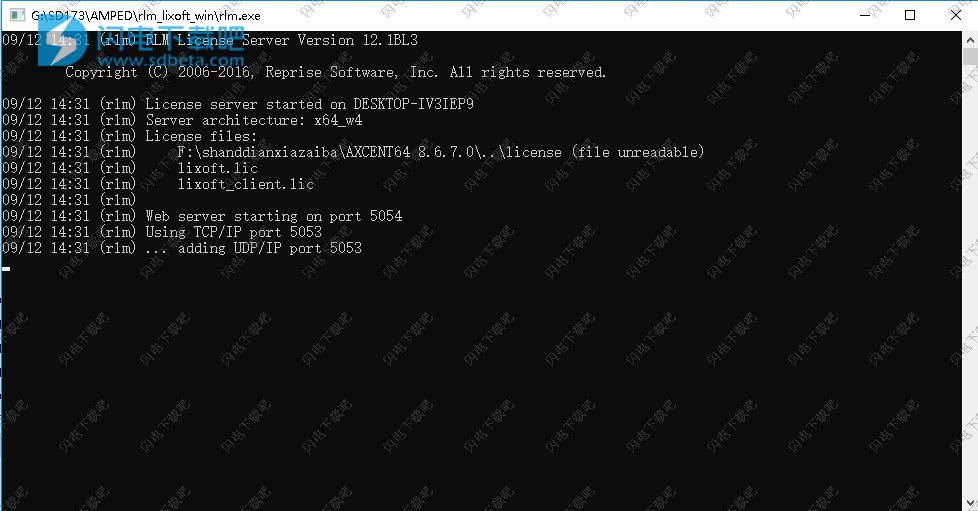
3、双击monolixsuite2018R2-installer.exe运行, 点击next
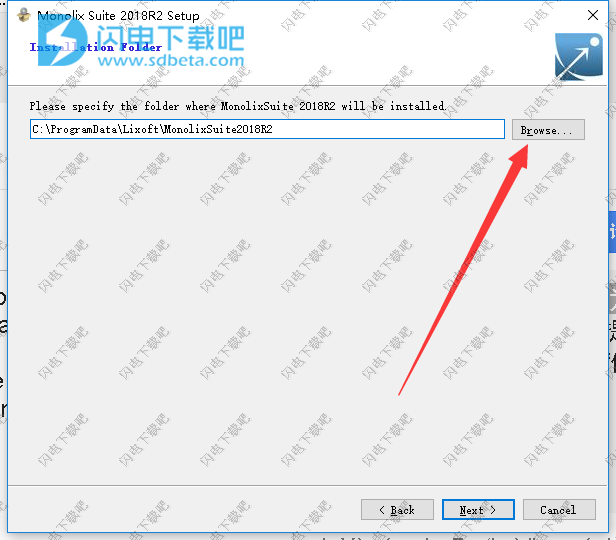
4、点击浏览选择安装路径,点击next
5、勾选我接受协议,点击next
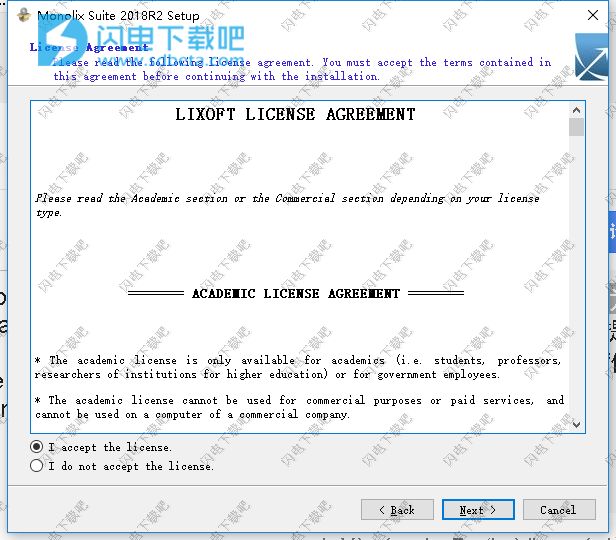
6、点击install安装
7、安装中,耐心等待一会儿
8、
要求提供激活码时跳过,点击next
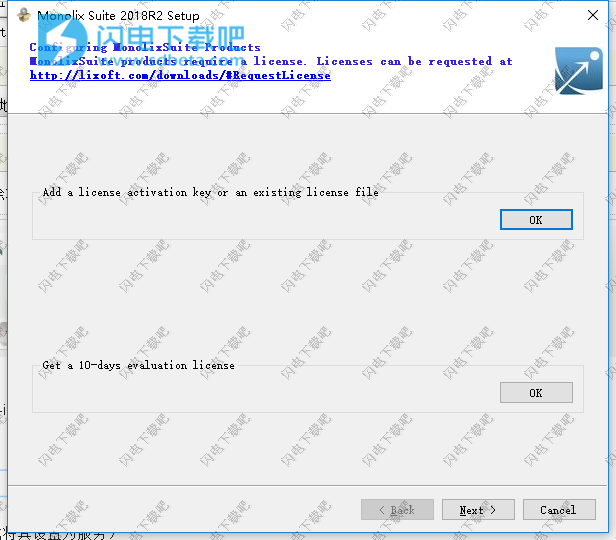
9、安装完成,点击finish退出向导
10、
在第一次启动期间,选择“With license file使用许可证文件”并指向破解文件夹中的lixoft_client.lic许可证文件即可
软件功能
1、高级统计方法
所有类型数据的可靠融合是人口PKPD建模的核心,这也是Lixoft与Inria合作开创SAEM算法的原因。
2、自动生成诊断测试
即使对于复杂的PK / PD模型,Monolix也会自动生成一整套诊断图。例如,您可以即时创建Visual Predictive Check,由您想要调查的任何患者子组拆分。
3、提高生产力和质量
高效的C ++求解程序包,带有Mlxtran的标准化模型语言,PK / PD模型库和集成软件都有助于提高生产率和质量。
4、它的GUI非常易于使用
我们的解决方案旨在方便使用。 Monolix可以通过图形界面或命令行使用,以实现强大的脚本编写。这意味着您可以减少编程,更多地专注于探索模型和药理学,以便及时为您的客户提供服务。
软件特色
1、支持所有相关数据类型和统计功能
Monolix涵盖了用于群体PK / PD建模的各种数据类型和统计特征。对于所有情况,已经制定并公布了正确的统计方法以供参考。 Monolix涵盖:
连续,分类,计数和重复的事件数据时间。
混合物模型和模型的混合物。
具有任意数量级别的场合间变化。
正确处理BLQ数据。
各个参数的正态,对数正态,logit,概率和用户定义的分布。
2、Mlxtran
Mlxtran用于定制模型;一种简单但功能强大的模型语言,适用于简单和复杂的系统药理学模型。 Monolix提供了一个完整记录的开源库,包含126个PK和47个PD模型。
全面的文档和示例
我们非常谨慎地为用户提供全面的文档,包括方法,软件手册,教程,......
包含模型和数据的大量示例可用作模板来启动您自己的项目。
3、数据集
数据集是参数估计的关键元素,是汇总文件中实验数据的关键要素。因此,这里提出了Datxplore和Monolix数据集的专用网站。
4、使用Mlxtran的模型构造
Mlxtran用于定制模型;一种简单但功能强大的模型语言,适用于简单的PK以及复杂的系统药理学模型。模型文件包含结构模型,观察模型,单个参数定义和协变量定义。提出了用于Mlxtran语法的专用网站。
Mlxtran还包含一组用于PK / PD模型的宏和库。快速直观地定义模型非常有用。点击查看更多。
5、Monolix,易用性和强大的计算能力
我们的解决方案旨在方便使用。 Monolix可以通过图形界面或命令行使用,以实现强大的脚本编写。这意味着您可以减少编程,更多地专注于探索模型和药理学,以便及时为您的客户提供服务。界面很简单,有几个步骤可以完成所有项目。这里提出了Monolix文档的专用网站。
MonolixSuite 2018R2发行说明
2018年7月27日
该文档是MonolixSuite2018R2的发行说明,包含MonolixSuite2018R1的错误修复以及数据集和Mlxtran管理。
1、数据
*如果直接接受默认标题识别,即使已经识别为IGNORE,也会拒绝CMT数据列标题。
* EVID = 4和SS = 1的SS规则已更改,现在始终添加SS剂量。
*'c'不再被认为是协变量的别名。
*在将“已忽略的观察”更改为“忽略”之后,“观察”列中的黑曜数现已更新。
*如果数据集中没有时间列或回归列,则按主题划分未正确完成。
2、Monolix项目
*改进了使用在数据集中无效的协变量的[load]错误消息(例如,仅一个类别)。
* [load]现在可以正确完成加载错误项目错误后重新加载条件分发任务的数字模拟参数设置。
* [load]未正确重新加载估计条件均值的摘要。
* [导出/保存] mlxtran项目文件中的初始估计值现在以1e-16精度保存。重新加载时使用的输出文件保存在1e-16。在1e-6重新加载时未使用的3、输出文件。
* [导出/保存]默认导出路径现在使用已保存项目的完整基本名称(例如project.1.mlxtran的project.1)。
* [导出/ Simulx]修复错误的观察顺序w.r.t.适用于simulx的ytypes(monolix2simulx)。
* [首选项]当更改首选项设置时,项目不再被标记为已更改(项目名称中的星号)。
* [日志]导入/导出任务期间出现的错误,警告和信息(例如,在重新加载时读取输出文件或无法写入输出时)现在会通知gui。
* [load]数据集中的所有观察类型都可供将来使用。 “[CONTENT]”中缺少的名称将获得默认名称,并假定其具有连续值。它可以简化具有比当前输出更多输出的模型的切换。
* [export]预测现在正确写入bsmm模型的predictions.txt文件中
* [export]修复错误模型分布不正常时predictions.txt中的错误iwres值
3、模型
* [模型库]在联合口服/血管外和推注/输注给药的PK和PKPD文库中,添加具有生物利用度的模型。
* [模型库]在TMDD库中,添加了具有传输隔间的模型。
* [FIT]现在正确地完成了几个离散观测模型的观测和输出之间的拟合。
* [模型库]一些PKPD文件名被严重解析导致错误的过滤
4、初步估计
* [检查初始估计]没有输入测量的ID显示为空图。他们现在被删除。
* [检查初始估计]更改输出后分页无效
5、GUI
*在场景和评估运行期间,现在禁用项目菜单条目中的新建和加载
*在情景和评估运行期间,初始估算选项卡现已锁定
*固定参数现在在评估初始化对话框中显示为只读值
*现在可以在SAEM的设置中更改最大迭代次数和无变量参数的容差。
6、交易算法
* [SAEM]当有几个bsmm的观测模型时,SAEM之后不再有崩溃
* [SAEM] IOV:修复一些参数在ID级别没有变化且没有使用协变量的情况
* [SAEM] IOV:修复一些参数根本没有变化,选择“第一阶段的可变性”在pop中选择。参数设置,并且没有参数在最后一级具有可变性(例如,列标记为偶然但没有定义iov)
* [SAEM] IOV:修复不是最后一个的可变性等级是否为空(例如,没有任何参数具有iiv)
* [SAEM] IOV:修复一些参数没有个体间变异性,没有参数在最后一级具有变异性,并且在saem的设置中选择了人为变异性:有时人工变异可能达到非常小的值,导致参数切换到探索阶段最大迭代次数的80%。
* [SAEM]更新了模拟审查方法,以更好地管理极值
* [全部]模拟审查现在每个链都不同。在恒定误差模型的情况下,这可以稳定收敛。
* [Loglikelihood] IOV:当最后一个方差水平未满时修复重要性采样(例如某些参数没有iov)
* [Loglikelihood]如果存在多个链和贝叶斯先验,则修复LogLikelihood计算。
* [MPI] Threads选项为monolix mpi分发
* [结果/标准误差]不再考虑特征值的潜在概率
* [结果/测试]统计测试的稳健性得到改善。
* [结果/测试]计算分类协变量的ANOVA测试不再崩溃
* [结果/测试]统计测试中禁用值的安全性(Pearson)
* [FISHER]如果只有潜在的协变量估计参数,计算Fisher信息矩阵不会再崩溃。
* [FISHER]如果存在固定的参数导数中的nan,则在随机近似中去除错误警告。
7、地块
* [全部]仅运行一个绘图时,现在显示进度条的显示。
* Windows上现在支持[全部] gamma unicode字符。
* [全部]当绘图生成中出现错误(例如生成nan)时,错误消息现在在通知中提供给用户。
* [所有]点现在从对数标度中排除,与epsilon相比而不是零。这可以防止所有点在x或y轴上被挤压。
* [全部]计算公共域时不再考虑空图表(“相同限制”设置)
* [全部]更改刻度字体大小后,刻度和轴之间的间隙现在更新。
* [输出图]在信息对话框中不再考虑没有观察的个人。
* [个人配合]当根本没有变化时,个别配合没有很好地绘制(黑色窗口)
* [个人适合]当只有一次观察的对象没有加入场合时,时间网格被严格定义。
* [个人适合]有几个观察模型和IOV,如果一个模型的主题场合没有观察,也没有回归,但是剂量,这个场合的连接很糟糕。
* [残差]截断数据用于二进制计算,即使相应的切换设置为'假',因此在'useCensoredData'切换更改后未更新二进制位。
* [残差]在bsmm情况下,IWRES计算现在在SAEM和/或IndivEstim之后更新。
* [residuals]修复bsmm情况下的计算
* [残差] npde计算:当pwres和几个模拟残差相等时改进秩定义(取中间位置而不是upper_bound(mlxsuite2018R1)或lower_bound(mlxsuite2016))
* [随机效应]潜在协变量随机效应的分布现在是正确的
* [全部]修复后的bsmm模型的错误观察值
* [预测检查]当分层导致空子图时,预测间隔建立不再崩溃
* [图表导出]当分割图上有预测区间时,所有子图的所有预测区间都被修正导出为SVG图。
* [图表导出]我们现在在导出图形时嵌入GUI中使用的字体。
* [图表导出]我们现在导出图例(在图表图像文件或单独的文件中)
* [导出图表数据/观察与预测] xxx_visualGuides.txt中有一个额外随机填充的列。
* [导出图表数据/残差分布]:在图表数据表中,当使用“条件分布”时,iwRes的列具有正确的长度,并且每个人有多个值。
*当垃圾箱数量固定时,[箱柜]不会尝试在每个箱子条件下适应maximumNbOfPoints
* [Bins]修复计算功能。如果数据点太相似(例如残差的散点图),可防止崩溃
*在新图表中“另存为”后使用上次保存的设置
8、分层
*自动连续组大小现在可以防止它们为空长度
9、MlxConnectors
* initializeMlxConnectors():未找到dll时改进的错误消息
*管理.encodeNumericals()中的多维数组
*初始化失败时卸载mlxConnectors库。这可以防止用户杀死licenseActivate窗口时出现不一致的行为
*错字修正
* computePrediction():不再抑制individualParameters输入dataFrame的第一列。这导致computePrediction的输出值错误。
* newProject():在数据验证之前考虑在参数中传递的头类型。当默认标记为数据集不正常时,这可以避免错误。
10、Mlxtran
* EVID = 3时重置错误
*如果定义了t0(ODE从t0开始而不是从t开始)
*用于TTE或连续马尔可夫链(丢失经过时间的历史记录)
*使用回归量的TTE模型的模拟存在问题
*分析解决方案不使用IOV参数值,即使是冲洗或新的时间段
*如果场合没有模拟事件,则IOV会出现TTE图形不稳定
*接受非常大的整数,转换为双精度浮点值。这允许安全地保存 - 重载非常大的双精度值而不包含小数。
11、Mlxplore
*我们现在考虑mlxplore最近文件中的新保存项目(来自monolix项目)
*即使存在没有<DESIGN>的<DATAFILE>,也要使用<OUTPUT>部分中的时间网格。没有剂量。
12、Mlxeditor
*“bsmm”关键字现已得到广泛认可










