Xilinx Vitis AI破解版使软件开发人员能够跟上AI创新,并统一从边缘到云的AI应用程序开发。它由优化的IP内核,工具,库,模型和示例设计组成。它在设计时考虑了高效和易用性,充分发挥了Xilinx FPGA和自适应计算加速平台(ACAP)上AI加速的全部潜力。通过抽象出底层FPGA和ACAP的复杂性,它使不具备FPGA知识的用户更容易开发深度学习推理应用程序。Vitis AI开发环境是Xilinx的开发平台,用于在Xilinx硬件平台(包括边缘设备和Alveo卡)上进行AI推理。它由优化的IP,工具,库,模型和示例设计组成。包含众多组件,如一组全面的预优化模型、可选的模型优化器、功能强大的量化器、AI编译器、对AI推理实现的效率和利用率进行深入分析、AI库、高效且可扩展的IP内核定制等!
主要优势
1、支持主流框架和能够执行各种深度学习任务的最新模型。
2、提供一套全面的预优化模型,这些模型可随时部署在 Xilinx®设备上。
3、提供功能强大的量化器,支持模型量化,校准和微调。对于高级用户,Xilinx还提供了可选的AI优化器,该模型可以将模型削减多达90%。
4、AI Profiler提供了逐层分析以帮助解决瓶颈。
5、AI库提供统一的高级C ++和Python API,以实现从边缘到云的最大可移植性。
6、定制高效且可扩展的IP内核,以从吞吐量,延迟和功耗的角度满足您对许多不同应用程序的需求。
功能特色
1、您的开发如何与AI配合使用:
支持主流框架和能够执行各种深度学习任务的最新模型
提供了一套全面的预优化模型,这些模型可随时部署在Xilinx设备上。您可以找到最接近的模型并开始对您的应用程序进行重新训练!
提供功能强大的量化器,支持模型量化,校准和微调。对于高级用户,我们还提供了可选的AI优化器,该模型可以将模型裁剪多达90%
AI Profiler提供了逐层分析以帮助解决瓶颈
AI库提供了高级C ++和Python API,以实现从边缘到云的最大可移植性。
可以自定义高效,可扩展的IP核,从吞吐量,延迟和功耗的角度满足您对许多不同应用程序的需求
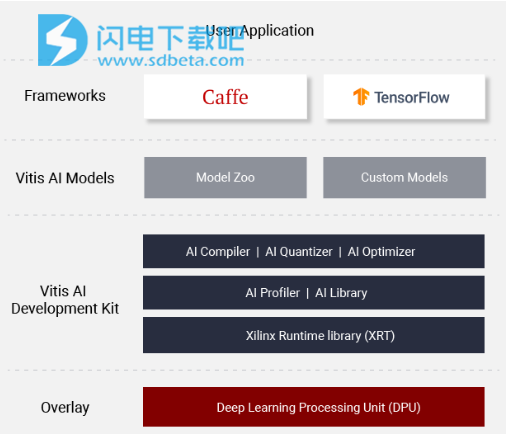
2、Vitis AI模型动物园
Tensorfilow和Caffe的丰富模型
在Github上对所有开发人员免费开放
应用了高级优化,包括修剪
可自定义数据集
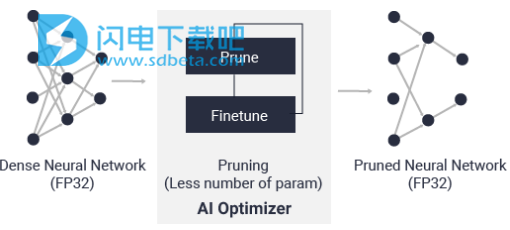
3、AI优化器
借助世界领先的模型压缩技术,我们可以将模型复杂性降低5倍至50倍,而对精度的影响最小。深度压缩将AI推理的性能提升到一个新的水平。
4、AI量化器
通过将32位浮点权重和激活转换为INT8之类的定点,AI Quantizer可以降低计算复杂度,而不会损失预测精度。定点网络模型需要较少的内存带宽,因此比浮点模型提供更快的速度和更高的电源效率。
5、AI编译器
将AI模型映射到高效的指令集和数据流。还执行复杂的优化,例如层融合,指令调度和尽可能多地重用片上存储器。
6、AI Profiler
通过性能分析器,程序员可以对AI推理实现的效率和利用率进行深入分析。
7、AI图书馆
运行时提供了一组轻量级的C ++和Python API。轻松进行应用程序开发。它还提供有效的任务调度,内存管理和中断处理。

使用帮助
使用ML框架加速子图
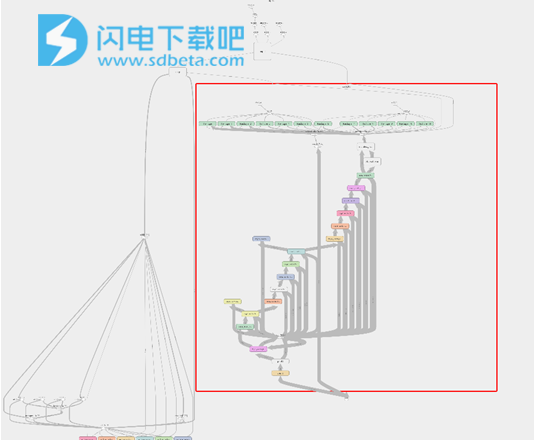
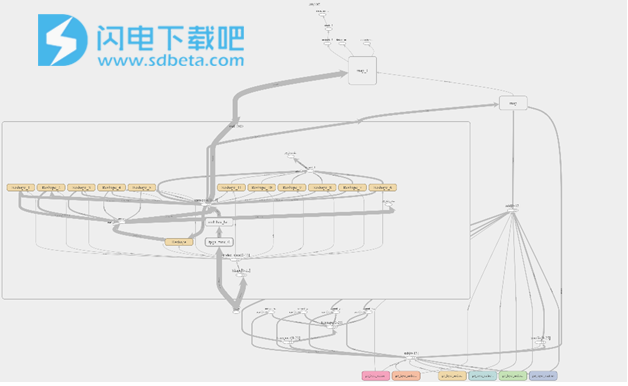
分区是在FPGA和主机之间拆分模型的推理执行的过程。要执行包含FPGA不支持的层的模型,必须进行分区。分区对于调试和探索不同的计算图分区和执行以满足目标目标也很有用。以下是基于Resnet的SSD对象检测模型的示例。请注意,原始图(图1)中的红色部分已由fpga_func_0分区图(图2)中的节点所取代 。分区的代码已完成,并且可以在CPU和FPGA上执行。
注意:此支持当前可用于基于Alveo™的深度学习解决方案。
图片:原始图
图片:分区图
1、在TensorFlow中对功能性API调用进行分区
图分区的一般流程如下:
创建/初始化分区类:
from vai.dpuv1.rt.xdnn_rt_tf import TFxdnnRT
xdnnTF = TFxdnnRT(args)
加载分区图:
graph = xdnnTF.load_partitioned_graph()
像加载原始图形一样应用预处理和后处理。
2、分区器API
分区程序的主要输入参数(例如,“分区使用情况”流中项目1中的args)如下:
网络文件:tf.Graph,tf.GraphDef或网络文件的路径
loadmode:网络文件的保存协议。支持的格式[pb(默认),chkpt,txt,保存的模型)
quant_cfgfile:dpuv1量化文件
batch_sz:推断批大小。(默认1)
startnode:FPGA分区的启动节点列表(可选。默认为所有Placehoder)
finalnode:fpga分区的最终节点列表(可选。默认为所有接收器节点)
分区步骤:
加载原始图
分区程序可以处理冻结的tf.Graph,tf.GraphDef或网络文件/文件夹的路径。如果提供了pb文件,则应正确冻结图形。其他选项包括使用tf.train.Saver和tf.saved_model的模型存储。
分区
在此步骤中,将分析由起始节点和最终节点集指定的子图以进行FPGA加速。这是分多个阶段完成的。
使用以下两种方法之一将所有图形节点划分为(FPGA)支持和不支持的集合。默认(compilerFunc ='SPECULATIVE')方法使用对硬件操作树的粗略估计。第二种方法(compilerFunc ='DEFINITIVE')利用硬件编译器。后者更准确,并且可以根据指定的选项处理复杂的优化方案,但是,花费大量时间才能完成该过程。
相邻的受支持节点和不受支持的节点合并为(细粒度)连接的组件。
受支持的分区合并到最大连接的组件中,同时保持DAG属性。
使用硬件编译器来编译(重新)编译每个受支持的分区,以创建运行时代码,量化信息和相关的模型参数。
存储每个受支持的分区子图是为了进行可视化和调试。
每个支持的子图都被tf.py_func节点替换(命名约定为fpga_func_ <partition_id>),该节点包含所有必需的python函数调用,以通过FPGA加速该子图。
冻结修改后的图
修改后的图将被冻结并以“ -fpga”后缀存储。
在Tensorflow中本地运行
可以使用partitioner类的load_partitioned_graph方法加载修改后的图。修改后的图将替换默认的张量流图,并且可以类似于原始图来使用。
实用笔记:
可以通过将适用的编译器参数通过位置参数或选项参数传递给Partitioner类TFxdnnRT来修改编译器优化。
如果未正确冻结模型,则编译器可能无法优化某些操作,例如batchnorm。
startnode和finalnode集应为顶点分隔符。意思是,删除startnode或finalnode会将图分成两个不同的连接组件(除非startnode是图占位符的子集)。
尽可能不要在作为单个宏层执行的层之间指定剪切节点,例如对于Conv(x)-> BiasAdd(x),将Conv(x)放置在与BiasAdd(x)不同的FPGA分区中次优性能(吞吐量,延迟和准确性)。
分区程序的初始化要求quant_cfgfile存在,以便能够为FPGA创建可执行代码。如果不打算执行FPGA,可以通过设置来规避此要求quant_cfgfile=”IGNORE”。
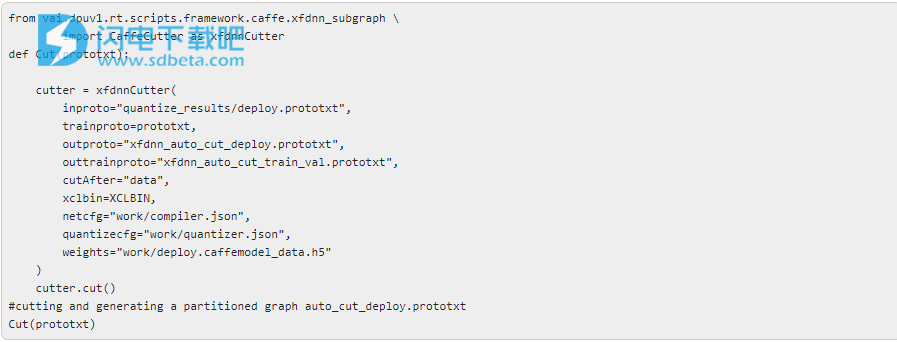
3、Caffe中的分区支持
Xilinx增强了Caffe软件包,可以自动对Caffe图进行分区。该函数将网络中的FPGA可执行层分开,并生成一个新的原型,用于推理。子图切割器创建了一个定制的python层,以便在FPGA上进行加速。以下代码片段说明了该代码: