风月读书是一款开源、无广告的小说阅读软件,内置15个书源,包括11个网络小说书源以及4个实体书书源,并能够自行制作添加书源,现在还具有语音朗读功能,看书累了还能听书,也是非常贴心了,支持快速搜书以及获取排行版,通过分类来查找你喜欢的书,感兴趣的朋友不要错过了!
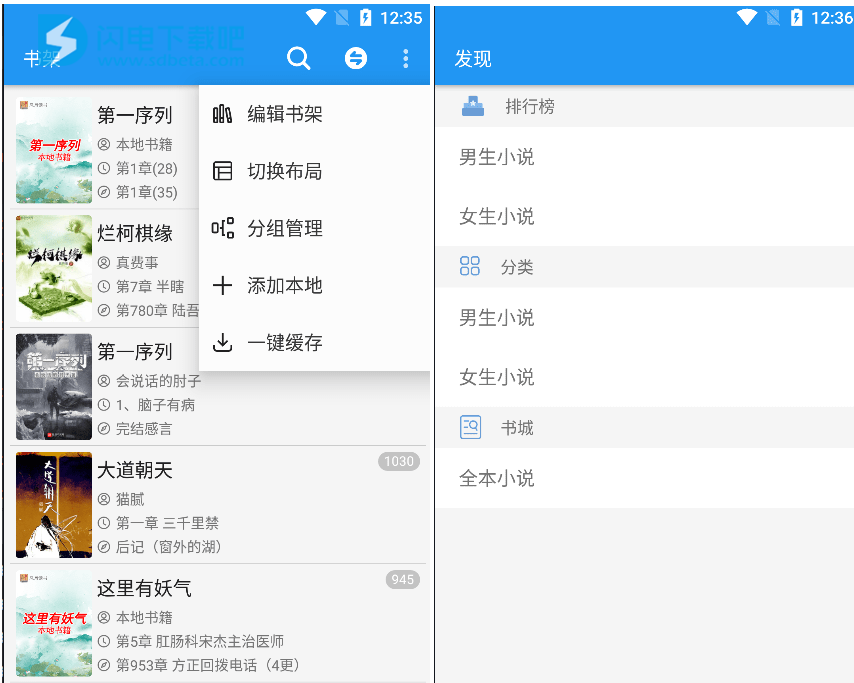
使用说明
1、软件内置了15个书源如下:
11个网络小说书源:天籁小说、笔趣阁44、品书网、笔趣阁、
全本小说、米趣小说、九桃小说、云中书库、
搜小说网、全小说网、奇奇小说
4个实体书书源:超星图书·实体、作品集·实体、99藏书·实体、100本·实体
2、如何自行制作并添加书源.
基于面向接口开发的思想,对于书源我设计了如下接口:
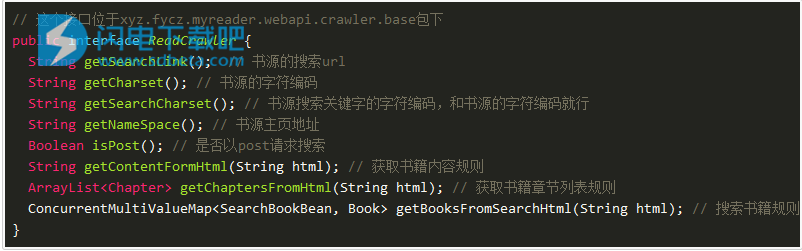
了解上述接口的方法,我们就可以开始创建书源了
第一步:创建一个书源类实现上述接口,下面以笔趣阁44为例进行说明
public class BiQuGe44ReadCrawler implements ReadCrawler, BookInfoCrawler {
public static final String NAME_SPACE = "https://www.wqge.cc";
public static final String NOVEL_SEARCH = "https://www.wqge.cc/modules/article/search.php?searchkey={key}";
public static final String CHARSET = "GBK";
public static final String SEARCH_CHARSET = "utf-8";
@Override
public String getSearchLink() {
return NOVEL_SEARCH;
}
@Override
public String getCharset() {
return CHARSET;
}
@Override
public String getNameSpace() {
return NAME_SPACE;
}
@Override
public Boolean isPost() {
return false;
}
@Override
public String getSearchCharset() {
return SEARCH_CHARSET;
}
public String getContentFormHtml(String html) {
Document doc = Jsoup.parse(html);
Element divContent = doc.getElementById("content");
if (divContent != null) {
String content = Html.fromHtml(divContent.html()).toString();
char c = 160;
String spaec = "" + c;
content = content.replace(spaec, " ");
return content;
} else {
return "";
}
}
public ArrayList<Chapter> getChaptersFromHtml(String html) {
ArrayList<Chapter> chapters = new ArrayList();
Document doc = Jsoup.parse(html);
String readUrl = doc.select("meta[property=og:novel:read_url]").attr("content");
Element divList = doc.getElementById("list");
String lastTile = null;
int i = 0;
Elements elementsByTag = divList.getElementsByTag("dd");
for (int j = 9; j < elementsByTag.size(); j++) {
Element dd = elementsByTag.get(j);
Elements as = dd.getElementsByTag("a");
if (as.size() > 0) {
Element a = as.get(0);
String title = a.text() ;
if (!StringHelper.isEmpty(lastTile) && title.equals(lastTile)) {
continue;
}
Chapter chapter = new Chapter();
chapter.setNumber(i++);
chapter.setTitle(title);
String url = readUrl + a.attr("href");
chapter.setUrl(url);
chapters.add(chapter);
lastTile = title;
}
}
return chapters;
}
public ConcurrentMultiValueMap<SearchBookBean, Book> getBooksFromSearchHtml(String html) {
ConcurrentMultiValueMap<SearchBookBean, Book> books = new ConcurrentMultiValueMap();
Document doc = Jsoup.parse(html);
Elements divs = doc.getElementsByTag("table");
Element div = divs.get(0);
Elements elementsByTag = div.getElementsByTag("tr");
for (int i = 1; i < elementsByTag.size(); i++) {
Element element = elementsByTag.get(i);
Book book = new Book();
Elements info = element.getElementsByTag("td");
book.setName(info.get(0).text());
book.setChapterUrl(NAME_SPACE + info.get(0).getElementsByTag("a").attr("href"));
book.setAuthor(info.get(2).text());
book.setNewestChapterTitle(info.get(1).text());
book.setSource(BookSource.biquge44.toString());
SearchBookBean sbb = new SearchBookBean(book.getName(), book.getAuthor());
books.add(sbb, book);
}
return books;
}
public Book getBookInfo(String html, Book book){
Document doc = Jsoup.parse(html);
Element img = doc.getElementById("fmimg");
book.setImgUrl(img.getElementsByTag("img").get(0).attr("src"));
Element desc = doc.getElementById("intro");
book.setDesc(desc.getElementsByTag("p").get(0).text());
Element type = doc.getElementsByClass("con_top").get(0);
book.setType(type.getElementsByTag("a").get(2).text());
return book;
}
}
第二步:注册书源信息。有两个地方需要注册:
1)在xyz.fycz.myreader.enums.BookSource类(这是个枚举类型)中添加你的书源的命名以及书源名称,例如:
biquge44("笔趣阁44")
软件内置的两个发现源:
某点的排行榜、分类,全本小说网
制作发现源方法与书源类似,在此不再赘述










